Om het Vlaamse energiebeleid aan te passen en te funderen heeft het Vlaamse Energie- en Klimaatagentschap (VEKA) nood aan volledige en betrouwbare data. Deze data bestaat vooral uit informatie over de energieperformantie van gebouwen en gegevens over groene energieproductie in Vlaanderen. Daarnaast willen zij deze gegevens op een uniforme en eenvoudige manier kunnen rapporteren aan interne medewerkers, andere overheidsinstellingen, de energiesector, de industrie en de Vlaamse inwoners. De belangrijkste doelstellingen van dit platform zijn:
Al snel is de keuze gemaakt om een dataplatform op te zetten in de cloud. Deze beslissing is genomen door de vele voordelen die aan een cloudplatform vasthangen. De vier voornaamste voordelen zijn:
Zo is het nieuwe ‘Data Warehouse as a Service’ of kortweg ‘DWaaS’ van het VEKA geboren. In dit systeem wordt alle interne en externe data aangeleverd, verwerkt en opgeslagen. Gebruikers kunnen op het platform inloggen en de rapporten bekijken waar ze toegang tot hebben. Op de onderstaande afbeelding zie je de structuur van Dwaas, hier zullen we verder op inzoomen.
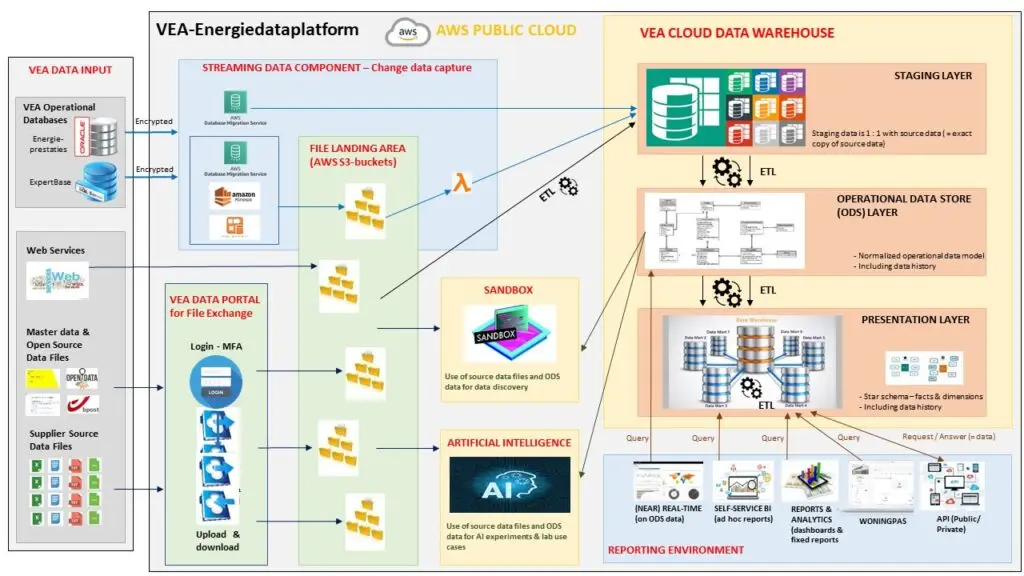
In het begin van de dataflow heb je natuurlijk de data input. In DWaaS komt zowel interne data als data van externe leveranciers binnen. Deze data wordt ofwel regelmatig (elke dag, elk uur, elke maand,…) opgeladen of stroomt in real-time binnen. Bestanden worden aangeleverd via het VEKA Data Portal, hier kan het VEKA gemakkelijk bestanden uitwisselen met hun leveranciers. Hierna stroomt de data door naar de file landing area waar we de brondata opslaan voor verwerking.
De data die binnenstroomt verwerken we zo weinig mogelijk om het op te slaan in de eerste laag van het datawarehouse (staging layer op de afbeelding). Zo kunnen we de originele data altijd terugvinden. Hierna voeren we de eerste transformaties uit op de data, we laten ETL tools los op de data. ETL staat voor Extract, Transform en Load. De relevante data wordt uit de brondata geëxtraheerd, dan transformeren we de data zodat het het juist formaat heeft. Zo kunnen we de kwaliteit en de uniformiteit van de data garanderen. Uiteindelijk laden we het op in de tweede laag datawarehouse (operational data store).
In de derde laag van het data warehouse transformeren we de data opnieuw om het in rapporten en dashboards te kunnen steken. Dit gebeurt volledig automatisch in Power BI. Gebruikers kunnen dan filters loslaten op de rapporten om zo de informatie te verkrijgen die voor hen relevant is. Iemand die voor de provincie Antwerpen werkt zou de rapporten bijvoorbeeld op deze provincie kunnen filteren om zo alleen de gegevens van Antwerpen te zien en niet van heel Vlaanderen.
In het midden staan twee blokken die we nog niet hebben besproken. In de sandbox, de zandbak, kan je experimenteren met data discovery. Dit wil zeggen dat je hier naar hartenlust kan experimenteren om nieuwe inzichten uit de data te kunnen halen. Zo ontdek je misschien verbanden waar je zelf nog nooit aan had gedacht. Als laatste zien we het AI blok staan, hier experimenteert het VEKA me artificial intelligence. Ze laten algoritmes los op data die zelf patronen in de data zullen ontdekken. Al deze nieuwe inzichten kunnen dan worden gebruikt om huidige maatregels aan te passen en om nieuwe beslissingen te onderbouwen.
De voornaamste doelstelling was om een platform te creëren waar alle data gestroomlijnd op één plek terechtkomt en op dezelfde manier wordt verwerkt. DWAAS is hier het perfecte antwoord op, het verzamelt de data van alle bronnen en brengt het samen in één centraal datawarehouse. Deze uniformiteit zorgt ervoor dat iedereen binnen en buiten het VEKA, naargelang hun toegang, dezelfde data op dezelfde manier te zien krijgt. Zo is er weinig ruimte voor misverstanden of andere interpretatie.
Een tweede belangrijke doelstelling was efficiëntiewinst. Een goed voorbeeld is de ondersteuning die het platform zal bieden voor de opmaak van het EPB-cijferraport van alle gebouwen in Vlaanderen waarvoor een stedenbouwkundige vergunning voor wordt aangevraagd. Alle grafieken en tabellen die nu manueel worden samengesteld zullen automatisch in Power BI worden gegenereerd. Zo staan de werknemers niet meer in voor de dataverwerking, maar kunnen zij zich richten op de interpretatie van deze gegevens.