This blog is Part 3 of a multi-part series around analyzing Flanders’ traffic whilst leveraging the power of cloud components! This miniseries was written in collaboration with Nick Van Hoof of TransIT.
This blog aims to explore the use of the AWS Glue service in conjunction with the AWS Athena service to repartition raw streaming data events. We previously landed these events on an Amazon S3 bucket partitioned according to the processing time on Kinesis.
However, we would like to have these events partitioned according to event timestamps to allow for meaningful batch analysis.
AWS Glue (which was introduced in august 2017) is a serverless Extract, Transform and Load (ETL) cloud-optimized service. This service can be used to automate ETL processes that organize, locate, move and transform data sets stored within a variety of data sources, allowing users to efficiently prepare these datasets for data analysis. These data sources can, for exmple, be data lakes in Amazon Simple Storage Service (S3), data warehouses in Amazon Redshift or other databases that are part of the Amazon Relational Database Service. Other types of databases such as MySQL, Oracle, Microsoft SQL Server and PostgreSQL are also supported in AWS Glue.
Since AWS Glue is a serverless service, users are not required to provision, configure and spin-up servers, and they do not need to spend time managing servers.
At the heart of AWS Glue is the Catalogue, a centralized metadata repository for all data assets. All relevant information about data assets (such as table definitions, data locations, file types, schema information) is stored in this repository.
In order to get this information into the Catalogue, AWS Glue uses crawlers. These crawlers can scan data stores and automatically infer the schema of any structured and semi-structured data that might be contained within the data stores, and also:
When data has been catalogued, it can then be accessed and ETL jobs can be performed on it. AWS Glue provides the capability to automatically generate ETL scripts, which can be used as a starting point, meaning users do not have to start from scratch when developing ETL processes. However, in this blog we will be focusing on the use of an alternative to the AWS Glue ETL jobs. We will be making use of SQL queries implemented in AWS Athena to perform the ETL process.
For the implementation and orchestration of more complex ETL processes, AWS Glue provides users with option of using workflows. These can be used to coordinate more complex ETL activities involving multiple crawlers, jobs and triggers. We will however be using an alternative to the these AWS Glue workflows, namely a state machine with step functions to coordinate our ETL process.
To reiterate, AWS Glue has 3 main components:
As mentioned above, our goals are the creation of an ELT pipeline which will repartition the data we already landed in an S3 data lake. This repartitioning will make sure the data is partitioned based on a timestamp within the event. This fits our analysis purposes as opposed to partitioning based on the timestamp at which the record arrived on kinesis firehose.
In order to achieve this we build an ETL job to extract the existing data from S3, transform it by creating new columns based on the event timestamp from within the data and land it in new partitions.
Specifically, the ETL jobs achieved the following:
To run this process continuously would not be very efficient. On the other hand, running this process not frequently enough (only once a week for example) would mean that we would have to wait too long to be able to report on new data.
We have a process of a few managed steps (running crawler, registering schema, executing ETL job, running crawler) that we need to orchestrate on a regular basis. Hence, it would be ideal for orchestration using AWS step functions.
In AWS Step Functions, you define your workflows in the Amazon States Language. The Step Functions console provides a graphical representation of that state machine to help visualize your application logic. States are elements in your state machine. A state is referred to by its name, which can be any string, but which must be unique within the scope of the entire state machine
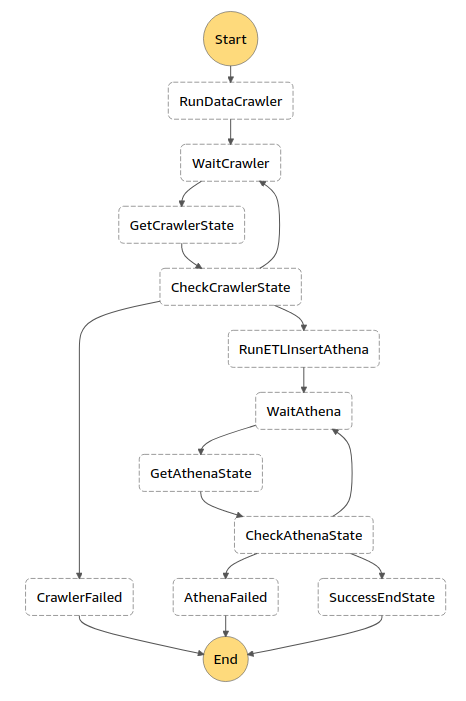
Here is overview of what our state machine looked like. As you can see, we have a finite number of steps executed one after the other.
ASL is a JSON based language to define the steps of your state machine. Later we will look deeper into the logic executed in each step. Let’s first look at the ASL that defines these steps.
AWS Sam and the Serverless Framework both allow you to specify the ASL as YAML. We found that using YAML improved readability. As such we defined our ASL as follows (complete ASL schema available here):
This ASL describes the same workflow as the state image above. It’s only much harder to read for human eyes.
Note that we indeed have the steps: running crawler, registering schema, executing ETL job and running crawler again. But we also have “wait” steps where we periodically check if a crawler is ready with his work. And we have failed states that we use to react to possible failures in our process.
Since this blog focuses on data and not on how to build state machines we’ll put a link here if you want to know more about AWS State Machines and Step Functions: click here.
Now it is time to look a little deeper into what happens during every step.
Tip: Choose descriptive names for your steps so that it is immediately clear what happens in a certain step.
Here are a few of our steps (again, check out the repository if you want to see all the logic):
RunDataCrawler This triggers the executing of a Lambda Function which in turn triggers a Glue Crawler
GetCrawlerState We are periodically checking the state of the running crawler. Since there is no direct integration for crawler events with step functions (yet?), we have to check this using a lambda function.
This returns the state of the crawler, thus telling us whether or not the crawler is finished. As you can see from the diagram and the ASL, we’ll use this status to make a choice for what is the next step to execute.
RunETLInsertAthena When the crawler is finished, it is time to run the ETL job. This is done using AWS Athena. Read more about the how and what of Athena in the next paragraph.
It is, however, the job of a Lambda function to start the ETL job in Athena and to check when it is finished.
The handler of the lambda function that starts the ETL job looks as follows.
The next function checks if the ETL job is finished. It does so by using the execution ID that was returned from the latest step.
The QueryExecutionIds from the previous step is now used to get the status of a specific query.
We saw the steps necessary in the workflow to repartition our data. This repartitioning was achieved with Athena. Let’s dive deeper into that in the next paragraph.
As stated above, we used AWS Athena to run the ETL job, instead of a Glue ETL job with an auto-generated script.
The querying of datasets and data sources registered in the Glue Data Catalogue is supported natively by AWS Athena. This means Athena will use the Glue Data Catalogue as a centralized location where it stores and retrieves table metadata. This metadata instructs the Athena query engine where it should read data, in what manner it should read the data and provides additional information required to process the data. It is, for example, possible to run an INSERT INTO DML query against a source table registered with the Data Catalogue. This query will insert rows into the destination table based upon a SELECT statement run against the source table.
Directly below we show part of our complete INSERT INTO DML query, which has additional nested subqueries in which data from the source table is transformed step by step so that it can be repartitioned and used for analysis.
The (part of the) INSERT INTO DML query shown directly above, performed the following:
The additional nested subqueries performed the following:
For a link to the complete INSERT INTO DML query, please refer to Github.
For a link to the explanation of field definitions, please refer to this link.
When using AWS Athena to perform the ETL job, as opposed to using Glue ETL jobs, there is no functionality to automatically start the next process in a workflow. Therefore we also implemented a polling mechanism in order to periodically check for crawler/ETL query completion.
As already mentioned several times, we could also have used Glue ETL jobs for the implementation of the ETL workflow. These ETL jobs handle all processing and repartitioning of the data through python scripts with Spark.
In our next blog in the series, we will explore the practical implementation of this alternative solution and compare the advantages, and disadvantages of the use of Glue ETL jobs vs. AWS Athena ETL queries for the implementation of ETL workflows.
This blog is Part 3 of a multi-part series around analyzing Flanders’ traffic whilst leveraging the power of cloud components.