Deze blog is deel 3 van een miniseries rond het analyseren van het verkeer in Vlaanderen en het benutten van de kracht van cloud componenten! Deze miniserie werd geschreven in samenwerking met Nick Van Hoof van TransIT.
Deze blog wil het gebruik onderzoeken van de AWS Glue service in combinatie met de AWS Athena service om ruwe streaming van data events te herverdelen. We hebben deze gebeurtenissen eerder neergezet op een Amazon S3 bucket verdeeld volgens de verwerkingstijd op Kinesis.
Wij zouden deze gebeurtenissen echter graag herverdeeld zien op basis van gebeurtenistijdstempels om een zinvolle batchanalyse mogelijk te maken.
AWS Glue (geïntroduceerd in augustus 2017) is een serverloze Extract, Transform and Load (ETL) cloud-geoptimaliseerde dienst. Deze dienst kan worden gebruikt om ETL-processen te automatiseren die datasets organiseren, lokaliseren, verplaatsen en transformeren die zijn opgeslagen binnen een verscheidenheid aan gegevensbronnen, zodat gebruikers deze datasets efficiënt kunnen voorbereiden op gegevensanalyse. Deze gegevensbronnen kunnen bijvoorbeeld data lakes zijn in Amazon Simple Storage Service (S3), data warehouses in Amazon Redshift of andere databases die deel uitmaken van de Amazon Relational Database Service. Andere soorten databases zoals MySQL, Oracle, Microsoft SQL Server en PostgreSQL worden ook ondersteund in AWS Glue.
Aangezien AWS Glue een serverloze dienst is, hoeven gebruikers geen servers beschikbaar te stellen, te configureren en op te starten, en hoeven zij geen tijd te besteden aan het beheer van servers.
Het hart van AWS Glue is de Catalogus, een gecentraliseerde metadata opslagplaats voor alle data-assets. Alle relevante informatie over data-assets (zoals tabel definities, data locaties, bestandstypen, schema informatie) wordt opgeslagen in dit archief.
Om deze informatie in de catalogus te krijgen, gebruikt AWS Glue crawlers. Deze crawlers kunnen data stores scannen en automatisch het schema afleiden van alle gestructureerde en semi-gestructureerde gegevens die zich in de data stores kunnen bevinden. Bovendien kan het ook:
Wanneer de gegevens zijn gecatalogiseerd, zijn ze toegankelijk en kunnen er ETL-taken op worden uitgevoerd. AWS Glue biedt de mogelijkheid om automatisch ETL-scripts te genereren, die kunnen worden gebruikt als uitgangspunt. Dat betekent dat gebruikers niet vanaf nul hoeven te beginnen bij het ontwikkelen van ETL-processen. In deze blog zullen we ons echter richten op het gebruik van een alternatief voor de AWS Glue ETL jobs. We zullen gebruik maken van SQL-queries die in AWS Athena zijn geïmplementeerd om het ETL-proces uit te voeren.
Voor de implementatie en orkestratie van complexere ETL processen biedt AWS Glue gebruikers de mogelijkheid om workflows te gebruiken. Deze kunnen worden gebruikt voor de coördinatie van complexere ETL-activiteiten waarbij meerdere crawlers, jobs en triggers betrokken zijn. Wij zullen echter een alternatief gebruiken voor deze AWS Glue-workflows, namelijk een toestandsmachine met stapfuncties om ons ETL-proces te coördineren.
Nogmaals, AWS Glue heeft 3 hoofdcomponenten:
Zoals hierboven vermeld, zijn onze doelstellingen het creëren van een ELT-pipeline die de gegevens die we al in een S3-data lake hebben neergezet, opnieuw zal herverdelen. Deze herverdeling zal ervoor zorgen dat de gegevens worden verdeeld op basis van een tijdstempel binnen de gebeurtenis. Dit past bij onze analysedoelstelling, in tegenstelling tot herverdeling op basis van het tijdstip waarop het record in Kinesis Firehose kwam.
Om dit te bereiken, bouwen we een ETL-taak om de bestaande gegevens uit S3 te halen, deze te transformeren door nieuwe kolommen te maken op basis van het tijdstempel van de gebeurtenis binnen de gegevens en deze te laten landen in nieuwe delen.
De ETL-taken bereikten het volgende:
Dit proces continu uitvoeren zou niet erg efficiënt zijn. Anderzijds zou het niet frequent genoeg uitvoeren van dit proces (bijvoorbeeld slechts eenmaal per week) betekenen dat we te lang zouden moeten wachten om over nieuwe gegevens te kunnen rapporteren.
We hebben een proces van een paar gerichte stappen (crawler uitvoeren, schema registreren, ETL-taak uitvoeren, crawler uitvoeren) dat we regelmatig moeten uitvoeren. Daarom zou het ideaal zijn voor orkestratie met behulp van AWS Step Functions.
In AWS Step Functions definieer je je workflows in de Amazon States Language. De Step Functions console biedt een grafische voorstelling van die toestandsmachine om jouw applicatielogica te helpen visualiseren. States zijn elementen in de state machine. Een state wordt aangeduid met zijn naam, die elke willekeurige string kan zijn, maar die uniek moet zijn binnen het bereik van de gehele state machine.
Hier is een overzicht van hoe onze state machine eruit zag. Zoals je ziet, hebben we een eindig aantal stappen die na elkaar worden uitgevoerd.
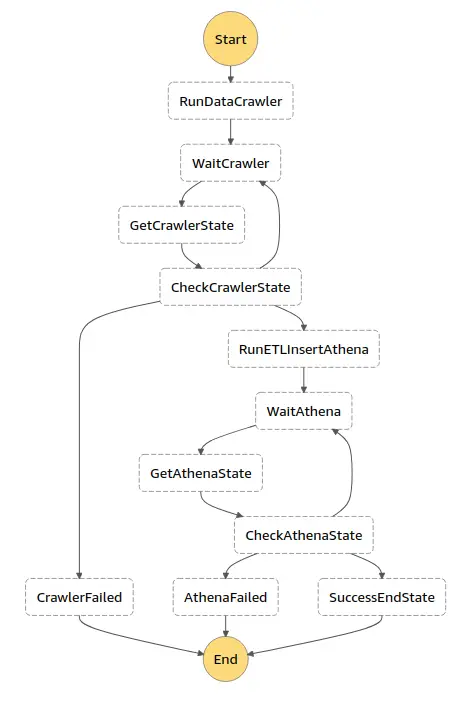
ASL is een op JSON gebaseerde taal om de stappen van je state machine te definiëren. Later zullen we dieper ingaan op de logica die in elke stap wordt uitgevoerd. Laten we eerst eens kijken naar de ASL die deze stappen definieert.
AWS Sam en het Serverless Framework staan beide toe dat je de ASL specificeert als YAML. Wij vonden dat het gebruik van YAML de leesbaarheid verbeterde. Daarom hebben we onze ASL als volgt gedefinieerd (het volledige ASL-schema is hier beschikbaar):
Deze ASL beschrijft dezelfde workflow als de afbeelding hierboven. Het is alleen veel moeilijker leesbaar.
Merk op dat we inderdaad de stappen hebben: crawler uitvoeren, schema registreren, ETL-taak uitvoeren en crawler opnieuw uitvoeren. Maar we hebben ook ‘wacht’-stappen waarbij we periodiek controleren of een crawler klaar is met zijn werk. En we hebben failed states die we gebruiken om te reageren op mogelijke fouten in ons proces.
Deze blog gaat over data en niet over hoe je state machines bouwt. Maar mocht je meer willen weten over AWS State Machines en Step Functions, klik dan hier.
Nu is het tijd om wat dieper in te gaan op wat er tijdens elke stap gebeurt.
Tip: kies beschrijvende namen voor je stappen, zodat het meteen duidelijk is wat er in een bepaalde stap gebeurt.
Hier zijn een paar van onze stappen (nogmaals, bekijk het archief als je alle logica wilt zien):
RunDataCrawler: Dit triggert het uitvoeren van een Lambda Function die op zijn beurt een Glue Crawler triggert.
GetCrawlerState: We controleren periodiek de status van de lopende crawler. Aangezien er (nog) geen directe integratie is voor crawler events met step functies, moeten we dit controleren met behulp van een Lambda functie.
Dit geeft de status van de crawler terug, en vertelt ons dus of de crawler klaar is of niet. Zoals je kunt zien in het diagram en de ASL, zullen we deze status gebruiken om een keuze te maken wat de volgende stap is om uit te voeren.
RunETLInsertAthena: Als de crawler klaar is, is het tijd om de ETL job uit te voeren. Dit gebeurt met behulp van AWS Athena. Lees meer over het hoe en wat van Athena in de volgende paragraaf.
Het is echter de taak van een Lambda-functie om de ETL-taak in Athena te starten en te controleren wanneer deze klaar is.
De handler van de lambda-functie die de ETL-taak start ziet er als volgt uit.
De volgende functie controleert of de ETL taak klaar is, door gebruik te maken van de uitvoerings-ID die werd teruggegeven van de laatste stap.
De QueryExecutionIds van de vorige stap wordt nu gebruikt om de status van een specifieke query te krijgen.
We zagen de stappen die nodig zijn in de workflow om onze gegevens te herpartitioneren. Deze herverdeling werd bereikt met Athena. Hieronder gaan we hier dieper op in.
Zoals gezegd hebben we AWS Athena gebruikt om de ETL job uit te voeren, in plaats van een Glue ETL job met een automatisch gegenereerd script.
Het bevragen van datasets en gegevensbronnen die in de Glue Data Catalogue zijn geregistreerd, wordt door AWS Athena ondersteund. Dit betekent dat Athena de Glue Data Catalogue gebruikt als een gecentraliseerde locatie waar tabelmetadata worden opgeslagen en opgehaald. Deze metadata instrueren de Athena query engine waar het data moet lezen en op welke manier het de data moet lezen, en geven aanvullende informatie die nodig is om de gegevens te verwerken. Het is bijvoorbeeld mogelijk een INSERT INTO DML query uit te voeren naar een brontabel die in de gegevenscatalogus is geregistreerd. Deze query zal rijen invoegen in de bestemmingstabel op basis van een SELECT statement tegen de brontabel.
Hieronder tonen we een deel van onze volledige INSERT INTO DML query, met aanvullende subqueries waarin gegevens uit de brontabel stap voor stap worden omgezet zodat ze opnieuw kunnen worden herverdeeld en gebruikt voor analyse.
De (deel van de) INSERT INTO DML query die direct hierboven is weergegeven, voerde het volgende uit:
De aanvullende subqueries voerden het volgende uit:
Voor een link naar de volledige INSERT INTO DML query, zie Github.
Voor een link naar de uitleg van de velddefinities, zie deze link.
Wanneer AWS Athena wordt gebruikt om de ETL job uit te voeren, in tegenstelling tot Glue ETL jobs, is er geen functionaliteit om automatisch het volgende proces in een workflow te starten. Daarom hebben we ook een pollingmechanisme geïmplementeerd om periodiek te controleren of de crawler/ETL query is voltooid.
Zoals reeds vermeld, hadden we ook Glue ETL jobs kunnen gebruiken voor de implementatie van de ETL workflow. Deze ETL jobs handelen alle verwerking en herverdeling van de gegevens af via python scripts met Spark.
In onze volgende blog in deze zullen we de praktische uitvoering van deze alternatieve oplossing onderzoeken en de voor- en nadelen vergelijken van het gebruik van Glue ETL jobs vs. AWS Athena ETL queries voor de uitvoering van ETL workflows.
Deze blog is deel 3 van een miniseries rond het analyseren van het verkeer in Vlaanderen en het benutten van de kracht van cloud componenten.