This blog is part 2 in our miniseries about processing real-time data. This miniseries was written in collaboration with Nick Van Hoof of TransIT.
The goal of this blog is to explore the use of the Amazon Kinesis Data Firehose service to load raw streaming data events on an Amazon S3 bucket (to create a data lake) in a format that lends itself to efficient batch processing. This way we will be able to analyze and visualize the streaming data over longer time frames.
The source data used for this purpose is traffic data, pulled from an API of the government of Flanders. We also used this data in our first blog about real-time data processing. In this blog and the next we will process data for using an ETL workflow.
As previously mentioned, our goal is to store our data on an S3 bucket. Luckily, Amazon Web Services provides two managed solutions that will allow us to achieve this: AWS Kinesis Firehose and AWS Kinesis Data Streams. Both services offer a similar yet different streaming solutions to transport and transform your data. Let’s explore the differences between these services.
Starting off with Data Streams, this service’s main properties are:
As we can see Data Streams are suitable for milliseconds latency real-time analytics. You have to manage the shards yourself, but you can automate this by using the Streams API.
The latter means that when using a Kinesis data stream, we are responsible for provisioning enough capacity on our stream via the provisioning of shards. You can find more info here.
Now let’s take a look at Firehose’s main properties:
Data Firehose is completely serverless and can be used for near real-time applications.
The current use case is to ingest the data and then convert it to the parquet format, and finally to land it on an S3 bucket for further batch processing. Kinesis Firehose is the service whose properties are best suited for this application.
If you want to explore the differences between Firehose and Data Streams in more detail, check the FAQ’s for Firehose and Data Streams
There are two main reasons that led to the choice of using the parquet file format (a columnar data storage format) to store the data on S3.
Firstly, the parquet format provides efficient data compression, leading to a reduction of the storage space. The amount of storage that is saved, will especially become more noticeable as the amount of data to be stored increases.
Secondly, this format is optimized for query performance. Which means that amount of data being scanned during querying will be significantly less as compared to querying data in, e.g., the JSON format. This will result in reduced costs when the data is queried for further batch processing.
As mentioned directly above using Kinesis Firehose allows us to transform the format of the records to parquet before landing the data on S3. Next, let’s look at the way in which the data is organized on S3.
The Kinesis Data Firehose service uses a UTC time prefix (in the form of ‘YYYY/MM/DD/HH’) by default to organize data when landing it on S3. It uses keys (separated by ‘/’ in the prefix) to determine the path by which an object can be found in an S3 bucket. Note that, even though these keys give the appearance of a folder structure, the AWS S3 structure does not work with folders. This way of organizing the data has several consequences:
To summarize, Kinesis Data Firehose uses processing time stamps to create partitions on S3 and it is not possible to utilize timestamps which derive directly from your data. In our next blog, we will explore how to repartition data on S3 in order to organize events according to timestamps which are contained within the data of the event itself.
As we just mentioned data will land on S3 in partitions named via the timestamp at which the data was processed by Kinesis. The Hive naming convention allows us to give our partitions a name.
Following the Hive naming convention for our partitions will allow us to give the partitions a functional name.
Here you see an example of an S3 key that follows his naming convention:
myOwnCustomS3Prefix/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/
As we can also see in the example above following the Hive specs the folder structure is of the format is /partitionkey1=partitionvalue1/partitionkey2=partitionvalue2
In the AWS console you can specify an S3 prefix for your firehose. In the picture below you can see this configured in the Kinesis console.
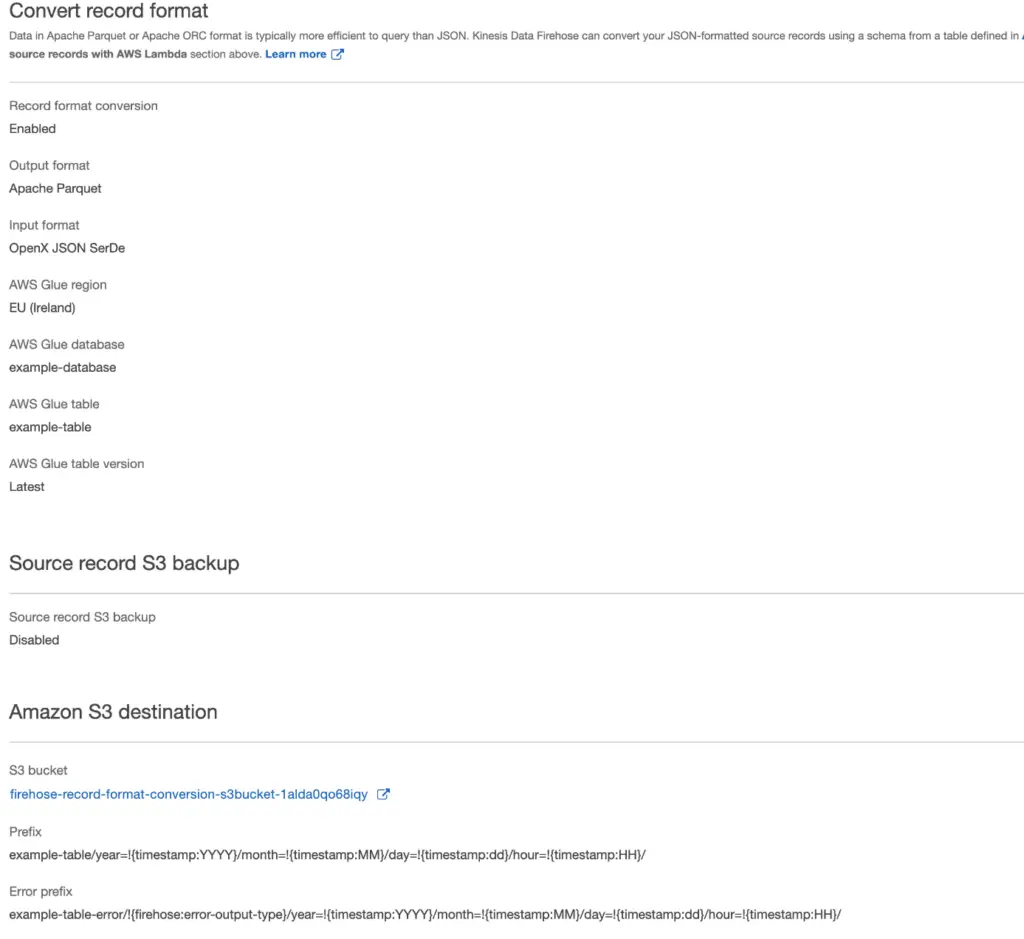
You could do everything mnually or you can automate all of this using cloudformation. Writing this cloudformation template isn’t that straightforward. This is why we provided a repository that you can deploy on your cloud account to get started. Find an example of how this is done.
We have achieved creating a data lake on S3. Our data lake is not ready yet to be used for analysis. We’d like to highlight the main takeaways from this exercise:
As mentioned before, our data is still partitioned according to processing time on kinesis instead of a timestamp coming from the data itself. This is why, our next step will be to repartition the data using a timestamp from the events. This will be explored in our next blog!
This blog is part 2 in our miniseries about processing real-time data. This miniseries was written in collaboration with Nick Van Hoof of TransIT.