In a world full of data, it can be difficult to find its value. With Cloubis, you effortlessly transform that abundance of data into clear insights. Together, we ensure that data becomes your strongest ally, allowing you to make better decisions and move your business forward.
We understand that data sometimes feels like a tangle, but that’s what we’re here for. With a backpack full of experience, our unique Data Platform Framework and powerful tools such as Azure Synapse, Databricks and Snowflake, we have helped many companies tame their data.
Our strength? We combine efficient, tailor-made solutions with a good dose of positivity. We focus on what is possible and ensure that you see results quickly.
Ready for a fresh look at your data with the best tools in the industry?
Request a demo now and discover the impact of data analysis on your business.
A data engineer is the architect behind your digital data. He transforms raw data into usable information, lays the foundation for data-driven decisions and optimizes data flows. Moreover, we go beyond just the technique. Our data engineers dive deep into your business challenges, streamline processes and create solutions that will really have an impact.
Working with a Cloubis data engineer means that you not only get advanced data infrastructures, but also a partner who thinks along with you to get the most out of that data.
Our approach
Integration
We start by actively merging all your data. Whether you work with structured databases, unstructured files, external APIs or streaming data, we integrate everything seamlessly. This gives you immediate uniform access to all crucial data.
Storage
We store your data safely and efficiently. Our scalable data platform can handle large data volumes while ensuring security, privacy and compliance. Whether you choose data lakes, lake houses or data warehouses, we find the perfect storage solution for you.
Analysis
With everything in place, we dive into the analysis. We know you want to gain deep insights from your data, whether it’s simple overviews or complex machine learning models. Our platform makes it possible, and our data engineers ensure that you can effortlessly and directly generate insights with your favorite tools.
Data Engineering Tools
In the world of data, the right tooling is essential. But what if you not only had access to the best tools, but also to a team that knows exactly how to use them optimally? That’s where we make the difference.
Process your data through an integrated open analysis platform.
Take your big data analysis and machine learning to the next level. Databricks is not just a platform; it is the place where you turn data into valuable insights. Thanks to the power of Apache Spark, you process data in the blink of an eye, and with intuitive dashboards you share your findings in no time.
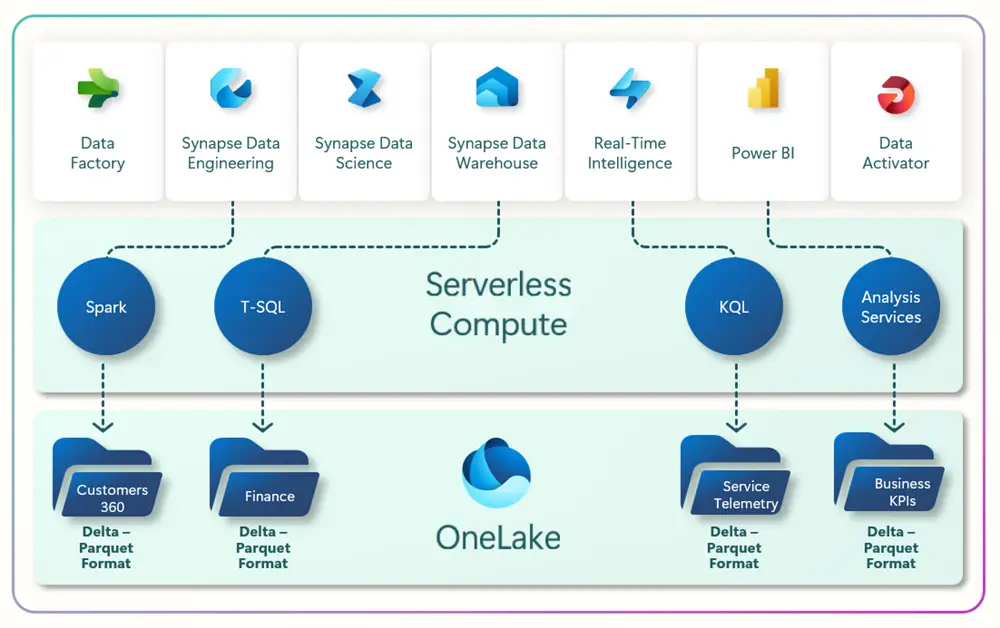
Microsoft Fabric is an end-to-end analytics and data platform designed for enterprises that require a unified solution. It encompasses data movement, processing, ingestion, transformation, real-time event routing, and report building. It offers a comprehensive suite of services including Data Engineering, Data Factory, Data Science, Real-Time Analytics, Data Warehouse, and Databases.
With Fabric, you don’t need to assemble different services from multiple vendors. Instead, it offers a seamlessly integrated, user-friendly platform that simplifies your analytics requirements. Operating on a Software as a Service (SaaS) model, Fabric brings simplicity and integration to your solutions.
DBT, or data build tool, is an open-source command-line program that helps with the development, testing, and maintenance of an organization’s data infrastructure.
With Cloubis, you bring a powerful partner into your home. Our ‘Team as a Service’ (TaaS)’ model puts a team of data specialists at your disposal. Data is the fuel for innovation, but it is the people and their processes that make the difference. That is why we focus on creating a culture in which data plays the leading role.
We support your team with the necessary knowledge and skills to see data as a strategic asset. At Cloubis, data is more than numbers and graphs; it is the key to growth and progress. We combine advanced technologies with practical insights to give your business a head start.
At Cloubis, it’s all about your success. Together, we build a strong foundation for your data-driven decision-making, equipped with the right tools and a data model that is perfectly tailored to your business needs.
Extensive expertise:
from strategy to governance
Find out how we can give your business an advantage with our diverse services.
Ready to discover the power of data analytics? We’re happy to answer all your questions and explain how we can transform your organization. During a live demo, we’ll show you how we can tailor our services to meet your specific needs.
When you fill out this form, one of our Data Engineers will contact you for a demo.
Frequently Asked Questions
What is data engineering?
Data engineering involves the design, development, and management of data architecture and infrastructures to efficiently collect, store, process, and analyze data.
What does a data engineer do?
A data engineer develops, builds, tests, and maintains architectures such as databases and large-scale processing systems. They improve the reliability, efficiency, and quality of data and ensure the architecture meets the business needs.
Why is data engineering important for businesses?
Data engineering is essential because it enables businesses to derive valuable insights from their data, support decision-making, optimize processes, and gain competitive advantage.
Which tools are used in data engineering?
Cloubis uses powerful tools like Azure Synapse, Databricks, and Snowflake to manage and analyze data. Our data engineers combine efficient custom solutions with a positive approach to achieve quick results.
How does data engineering contribute to business growth?
By transforming data into valuable insights, data engineering helps businesses make better decisions and progress.
Still have questions about how Cloubis can help your business with data?